Approaching Truth with GPT
 AI-Daleel landing page.
AI-Daleel landing page.
Recently, I released AI-Daleel, a GPT-powered al-Quran research tool. It is of utmost importance that any tool which aims to aid Islamic study adhere to the strict quality standards as shown to us by the tried and tested traditions of Islamic scholarship.
How reliable is the GPT architecture?
AI-Daleel is powered by OpenAI's GPT model, specifically the gpt-3.5-turbo model. It is a transformer-based large-language model trained through a technique called the Reinforcement Learning from Human Feedback (RLHF).
The GPT architecture is not designed to provide sources. Within the weights of the model, there is no information whatsoever regarding the source document from which it obtains a specific set of words. In fact, its job is to synthesize a sequence of text based on the "closeness" between words in its latent vector space and the dependencies between each word in a sentence (through the self-attention mechanism) throughout all domains that exist within the training corpus. For GPT-3, its training corpus is 570 GB of data of published texts on the internet, amounting to a word count of approximately 300 billion words.
Effectively, this means that during inference time of a zero-shot task (with no additional context provided in the prompt), it relies on the entirety of the corpus to generate the sequence of texts. With no additional context, the output would be heavily prone to hallucinations, as it is not bound with anything other than the word relationships it learnt during its initial training phase.
For example, if we instruct the model to generate a commentary on "Topic A", it will generate words that are semantically probable to come along with "Topic A" in its initial training corpus. Hallucinations will occur here as there are no specified boundaries between domains -- it is given free reign to choose from any domain in its training corpus. This is terrible for the purposes of Quranic translation summarization.
The good news is that hallucinations can be greatly reduced by providing more context to the model. This comes in the form of prompts that can be provided to the model during the instruction phase. The additional context serves as a specific set of instructions that enforces domain boundary for the text synthesis task.
The Bing approach
You might have used Bing's latest AI-infused search feature. We can see that it neatly provides references in the generated text. If GPT is not designed for referencing source documents, then how does Bing achieve this feature?
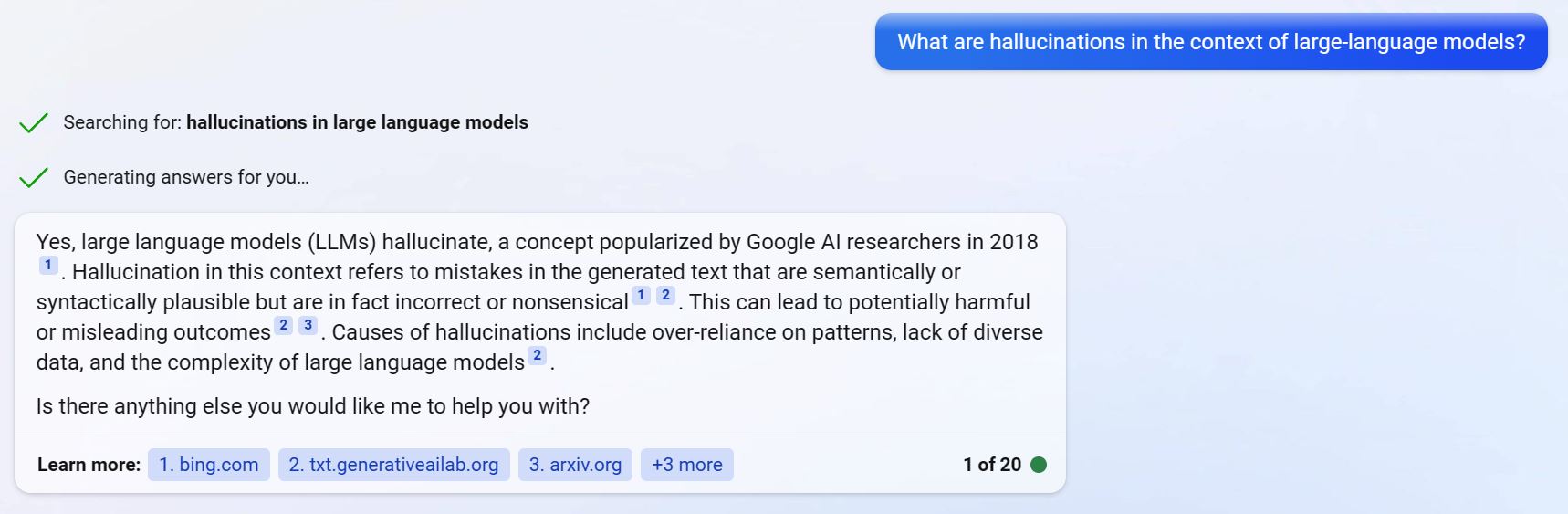 Bing's AI search.
Bing's AI search.
Bing relies on a method they coin as "grounding". A general form of this method is also known as retrieval-augmented few-shot prompting.
Without oversimplifying things too much, what happens is that they provide more context to the model by adding unstructured texts into the prompts. This is obtained from the retrieval component of the system. They do not disclose how their actual retrieval system works, but generically it would be a vector store of embeddings, which can be used to retrieve relevant documents based on the similarity of the input with the embeddings in the vector space — similar to how a conventional search engine works, albeit without the page rank component. It is also undisclosed how much SEO affects the references selected by Bing.
Essentially, the references provided by Bing are from the additional context texts obtained from its retrieval system, which are then injected into the prompts — not from the initial training data which exists in the weights and embeddings of the GPT model. It is important to distinguish between these two, and the reason for our avoiding for now this is explained in the following section.
How does AI-Daleel approach text synthesis?
Currently, there are two tasks that rely on GPT text synthesis in AI-Daleel. Namely, this is the AI Search feature and the AI Generate Notes feature.
Text Synthesis Task 1: AI Search
With the AI Search feature, the model is instructed to only return the surah numbers and verse numbers that are semantically related to the users input. The return object is a synthesized string that looks something like the following:
'[
{
"surah": 2,
"verse": 56
},
{
"surah": 12,
"verse": 23
},
{
"surah": 15,
"verse": 77
}
]'
We bring the model closer to Truth by avoiding text synthesis for the actual Quran verses and translations texts. With the surah and verse numbers provided above, we can use them to index a carefully curated dataset of Quran verse and translations stored in our database. AI-Daleel's verse texts and translations are sourced from the Tanzil project.
This way, the worst that can happen is we are given an index to a different verse than intended, rather than synthesizing a hallucination of a Quran verse that does not even exist.
Text Synthesis Task 2: AI Generate Note feature
The second task is the AI Generate Note feature. It must be made clear here that we do not summarize Quranic verses. Doing so would violate the discipline of Quranic study.
The AI Generate Note feature generates notes for the user based on the translation of the current verse. The translation text is provided as the additional context in the prompt. This way, the text synthesis task is bound by a specific domain/document, i.e. this specific translation text. In other words, the majority of the text generated will rely on the translation text for context, with the remaining portion relying on the initial corpus for linguistic elements like syntax, grammar, and ontology.
To reiterate, the source document used here is only the verse translation, as it is the only structured data we currently have that is verifiably held to an acceptable standard. Contrasting this to Bing's implementation, a reference link for context documents is not required here as there is only one context document that is provided in the prompt, i.e. the current verse's translation text.
Of course, we can mimic Bing's implementation by having more context documents through the inclusion of unstructured data from web pages into the prompt, but this comes at a risk of reduced reliability with unreliable sources of commentary. Search engine ranking is not a reliable metric for commentary reliability.
Without further context documents, the current drawback is that the summaries will be rudimentary paraphrasings of the verse translation. On the other hand, we avoid "poisoning the well" by not including any further context other than a reputable translation of the verse.
For the reasons mentioned above, we have made a conscious decision to avoid using any external references as context.
UI/UX considerations
It is important to let the users realize that any AI-generated text cannot be trusted as authoritative in any way. The AI Generate Note is a feature that generates notes on behalf of the user. To get this idea across, the translation summarization is generated in the user's input box, where the user can add and edit the generated text as they see fit before confirming the addition of the note.
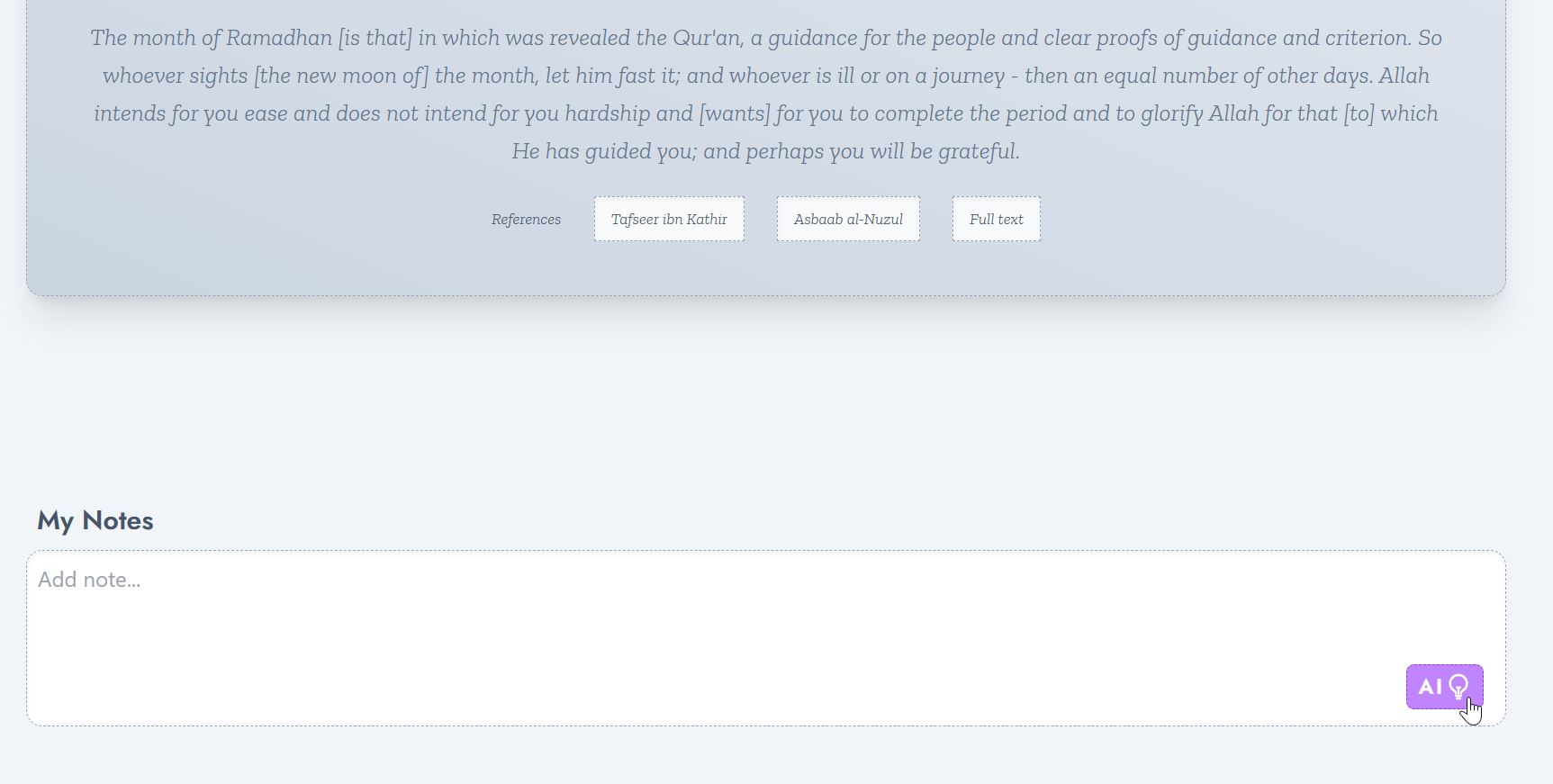 AI-Daleel's AI Note Generation feature.
AI-Daleel's AI Note Generation feature.
Possible improvements to consider
We are aware of the dangers and issues that come with unreliable summarization of the translation of Quranic text, and it is a matter we consider seriously throughout the development of this product. As of now, we are able to achieve a good level of reliability by limiting the context to only the verse translation, at a cost of a lower level of insights generated.
One possible pathway to improve insights generation without jeopardizing the reliability of context sources is to improve the al-Quran dataset we use by injecting structured (indexable) tafsir data like Tafsir Jalalayn and Tafsir al-Muyassar, both available from the Tanzil project, during the instruction phase. As our data is already structured with surah number and verse number as our indices, we might not need to make use of toolings like LangChain and vector stores to implement retrieval-augmented few-shot prompting. From a technical perspective, storing the structured tafsir data into embeddings would be pointless, as we do not need vector similarity to retrieve the documents — we already have one-to-one indices. In fact, doing so might even reduce the reliability of the generated text, as semantically similar tafsirs would be mixed together between different verses and Quranic contexts.
More research will need to be done behind the scenes with subject matter experts to verify the source documents before we can include this into our dataset. This way, we may be able to prevent unreliable, non-structured documents like the documents that would return from a search engine from reducing the overall reliability of the al-Quran translation summarization task.
With that said, as is the case with the translation of the meaning of al-Quran, no summary of the translation of the al-Quran is ever adequate. We can approach the Quranic Truth, but reaching it is not possible in the strictest sense of the word "adequate". Wallahua'lam.