Behind the Scenes of an AI App
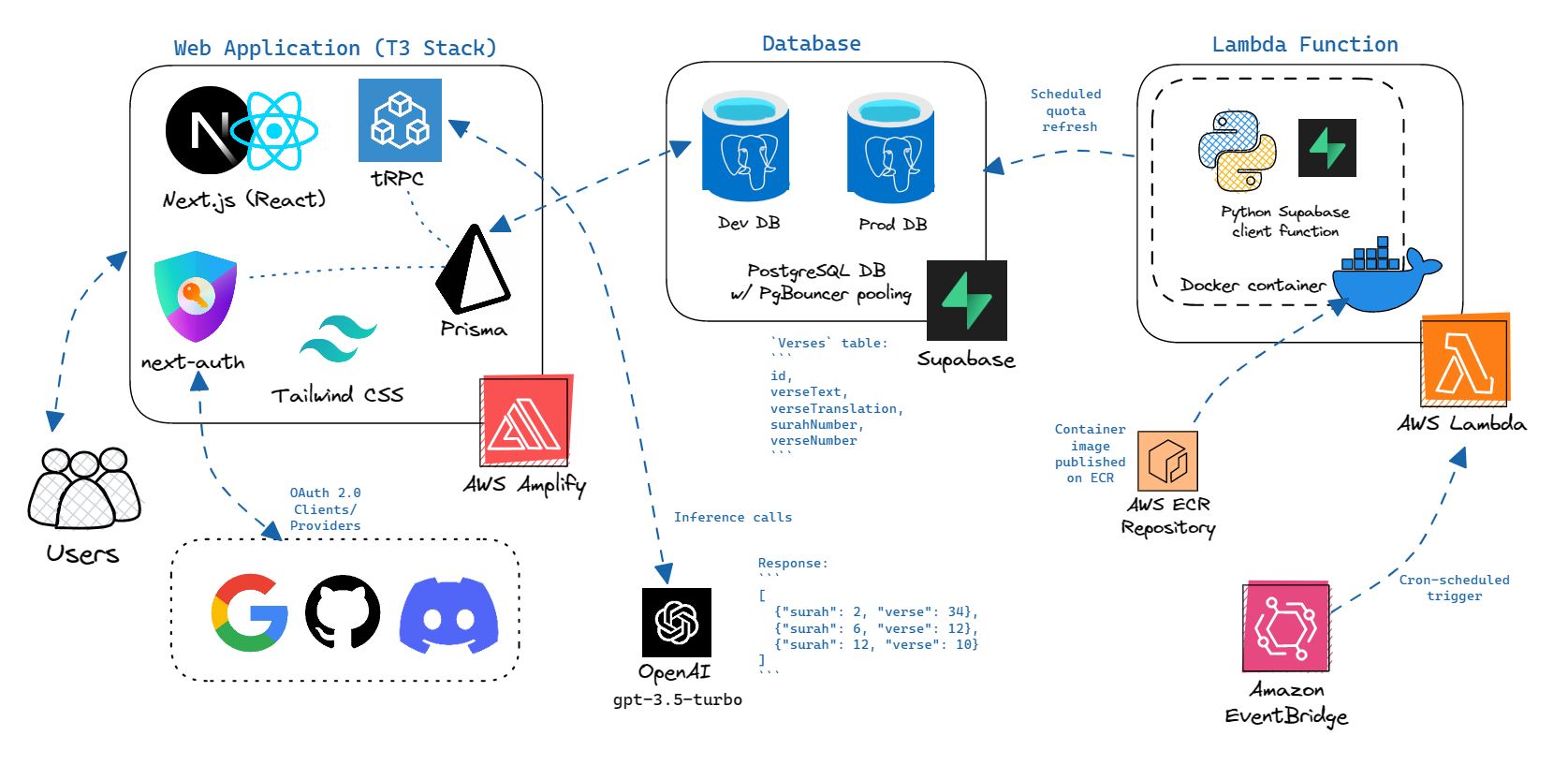 AI-Daleel system architecture.
AI-Daleel system architecture.
About AI-Daleel
Recently, I published AI-Daleel, a personal side project I have been working on in my free time in Ramadan. It's a tool that lets you search for Quranic verses with natural language search terms and rough transliterations.
It addresses a personal pain point of mine when it comes to Googling for Quranic verses. It's unreliable, messy, and slow. AI-Daleel aims to solve this.
On top of the search feature, AI-Daleel also lets you:
- Bookmark verses
- Add notes to your verses
- Generate notes based on verse translations
I have learnt a lot throughout the building of this project, and I would like to share it here to better cement the knowledge in my mind.
In this post, we will explore the system architecture of AI-Daleel, with a deep dive on the tech stack and cloud technologies used behind the scenes of AI-Daleel.
Core components
There are 3 core components that make up AI-Daleel:
- Web application — This is where the users interact with the system.
- Database — This is where the data is stored.
- Serverless function — This is how the quota refresh is implemented.
Web application
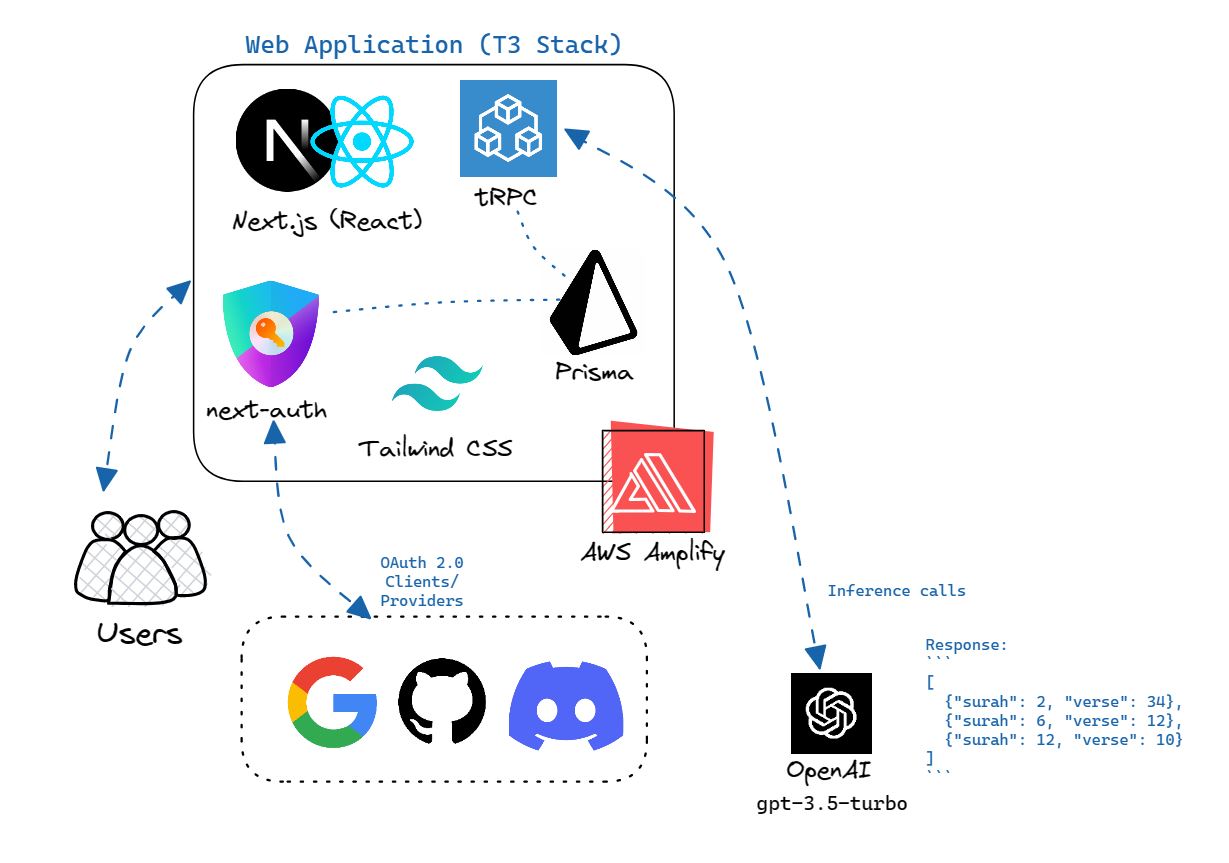 AI-Daleel web app stack.
AI-Daleel web app stack.
The web application is a TypeScript app built on the T3 stack. It is deployed on AWS Amplify Hosting, a cloud platform for hosting full-stack serverless web applications which comes with the whole continuous deployment (CD) shebang. It allows you to deploy your code simply by pushing to your GitHub repository. You can even enable preview deployments by connecting your feature branch to AWS Amplify. The build settings for deployments can be set using a config amplify.yml file, where you can define the pre-build and build commands, the base build directory, and your environment variables. As with most AWS products, it is also integrated with Amazon CloudWatch, where you can monitor the request logs for your application and perform traffic analytics.
For now, a serverless platform like AWS Amplify is the most economical option for deploying AI-Daleel as opposed to VPS/VM solutions like AWS EC2. On AWS Amplify, we are only billed for requests made to the application endpoints and the duration of build. On the other hand, if we were to deploy it into an EC2 instance, we will be billed for every second the server is running, regardless of the amount of traffic the application is receiving — and AI-Daleel is no Facebook.
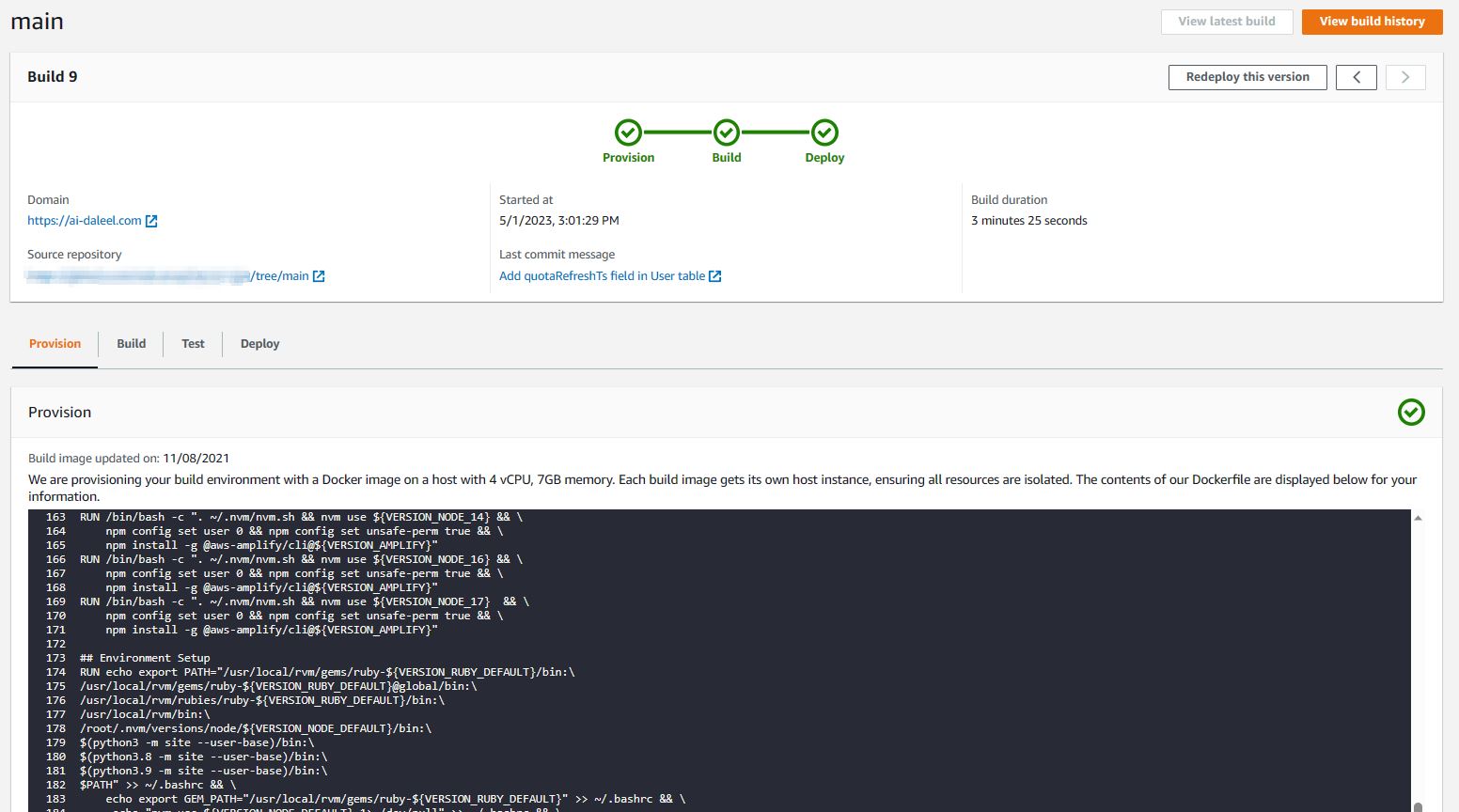 AWS Amplify deployment console.
AWS Amplify deployment console.
Naturally, being a Next.js project, it was initially deployed on Vercel — the company that created Next.js. However, on the eve of Eid, hours before release, the authentication procedure keeps on failing, preventing users from logging into the app. After troubleshooting well into the wee hours of Eid, it was found that the root cause for this failure is that the Serverless Function responsible for handling the authentication procedure with third-party auth providers keeps timing out due to extended cold starts, and there is no way to increase the timeout duration on Vercel.
After yeeting the code from Vercel and deploying it on AWS Amplify, with no change to the code at all, not only is it able to run the authentication procedure successfully, but all server-side fetches obtained a remarkable speed up over the Vercel deployment. This instantly turned me into an Amplify fanboy.
The web application code mentioned consists of the following components:
- Next.js
- tRPC
- Prisma
- Tailwind CSS
- NextAuth.js
- OpenAI API
Let's dive into each of these technologies.
Next.js
First off, Next.js is an open-source full-stack React framework that allows us to run both front-end and back-end code in a single repository. It comes with all the usual React goodness, such as client states handling, re-rendering, and componentization. Additionally, Next.js offers support for pre-rendering HTML documents on the server via Static Site Generation (SSG) and Server-Side Rendering (SSR), which can be configured independently for each page in the /pages directory. Next.js automatically defines a route for every file in this directory, as it uses folder-based routing instead of controller-based route definitions found in MVC frameworks.
SSG generates pages on the server at build time (during deployment) and serves them as static HTML documents. This means that when a user visits a page, they receive a pre-rendered HTML document (although data fetching and reactive client re-renders can still be done thereafter). For static pages, this approach can significantly improve the loading time and enhance SEO by providing fully-rendered HTML documents that search engine crawlers love. Next.js defaults to SSG for all pages, but you can implement SSG explicitly by defining rendering procedures, server-side fetches, and props in the getStaticProps function at the top of each page file. For dynamic routes, getStaticPaths is also required to let Next.js know what data to fetch based on all the possible routes.
SSR, on the other hand, renders pages on the server at runtime. This means that upon landing on a page, the client will send a request to the server for the HTML document. Logically, this approach has a slower time-to-first-byte as compared to SSG for static pages, and there is more server compute needed as each request gets a unique pre-render. However, for pages with a lot of data fetching and complex server-side logic, the time-to-first-byte can be faster than SSG. SSR is also best for instances where you need user-specific data to be rendered on the get-go, like authentication and authorization. To implement SSR in Next.js, you need to define the data fetching procedure in the getServerSideProps function at the top of your page file.
For AI-Daleel, only the landing page is rendered with SSG. This page does not require any complex server-side logic and data fetching at initial page load, and mainly contains static information. The client can then fetch the user session from the server after initial page load. For other pages, we opted for SSR as we want to protect the routes via authentication, mainly to prevent DDoS on the OpenAI API calls and implement user-level rate limiting. The /verse/[surah_verse] route also can't be rendered with SSG as there are too many verses to fetch from the database (6,236 rows to be exact), which could result in a terribly long build time, and more $$$ to Amazon.
export async function getServerSideProps(context: GetSessionParams | undefined) {
const session = await getSession(context)
//If no valid session, redirect to sign-in page.
if (!session) {
return {
redirect: {
destination: 'auth/signin',
permanent: false,
},
}
}
return {
props: { session }
}
}
Auth session check using getServerSideProps for protected routes.
As you see in the above code block, we can protect the whole page from being accessed with unauthenticated clients with getServerSideProps. This means that on page load, Next.js will return a redirect to the sign-in page if there is no valid session object available.
The rendering approach you choose with Next.js will depend on your application's specific requirements. A good mental model I use is to think about when do I need the data to be made available on the client-side. Then, you should also think about if the data is unique for each session or whether it is a static data that can be fetched once during build time. Ultimately, it is a matter of juggling between performance, availability, and complexity.
tRPC
Conventionally, API endpoints are communicated between the server and the client via RESTful JSON (or even XML). There is no way to ensure type-safety with REST, as it is essentially a string of JSON that you will have to parse on the client-side, which historically has been a huge source of headache for developers worldwide. tRPC fixes this.
tRPC is an open-source remote procedure call (RPC) framework designed for TypeScript. It allows for type-safe communication between front-end and back-end code using GraphQL-esque APIs without any code generation.
One of the key benefits of tRPC is that it ensures that the shape and types of the objects returned by the back-end is consistent with what is accepted by the client-side code, and vice versa. This eliminates the need to constantly switch between back-end and front-end files to ensure that the request and response shapes and types are aligned. Being able to hover over a tRPC method call and see the parameters it requires, what it returns, and the types involved is a good booster to DevEx.
Using tRPC also helps with keeping the response shape consistent. Instead of dealing with RESTful JSON, we are working with TypeScript objects that can be defined with types or interfaces. Ensuring a consistent response shape is critical for maintainability, readability, and iterability, and this is made simple with tRPC.
tRPC is built around react-query, preserving core functionalities such as useQuery and useMutation. At the risk of oversimplification, the way I think about it is that the former is used to make an API call to read data, and the latter is reserved for create, update, or delete operations. However, there are instances when read operations need to be done with useMutation, such as fetch calls that need to be made upon client-side state change within a React hook.
create-t3-app scaffolds a tRPC implementation that includes a middleware-level auth check via the protectedProcedure modifier alias, which checks if the session provided in the tRPC context is valid. This auth check will prevent the tRPC procedure from running if the session is invalid. Therefore, any client requests will only return a 200 response if a valid session is appended along with the tRPC request.
export const myRouter = createTRPCRouter({
//protectedProcedure only runs if there is a valid session in ctx.
myProcedure: protectedProcedure
.input(z.object({ verseId: z.string(), userId: z.string() }))
.mutation(async ({ ctx, input }) => {
let res: RespT; //Consistent base type
//Server-side logic here
return res
}),
})
Example of a tRPC protectedProcedure.
On the client side, we can call the above procedure like the following:
const myApi = api.myRouter.myProcedure.useMutation();
const handleUserClick = async () => {
res = await myApi.mutateAsync({ verseId: verseId, userId: userId })
}
In AI-Daleel, all database CRUD operations and OpenAI inference calls are implemented as tRPC procedures that are protected by middleware session authentication via protectedProcedure. This means that only requests from authenticated users with valid sessions are allowed, minimizing the risk of potential DDOS attacks. This security measure is crucial for preventing malicious attacks that could potentially bring down the site and result in significant financial losses.
Prisma
In modern web development, you do not want to write native SQL queries whenever the client needs data. For one, there are many database-specific flavours of SQL, and hard-coding SQL queries is an easy way to give future you more work when you decide to migrate to a different database. On top of that, it is easy to get things wrong and introduce severe security risks like SQL injection. SQL queries are also not strictly typed by nature, which goes against modern type-safety standards. The solution to all of this is the usage of ORMs.
Prisma is an open-source type-safe object-relational mapping (ORM) framework. Prisma Client performs database operations with TypeScript methods in place of native SQL queries. This comes with the benefit of type-safety, ensuring that the server-side query matches the data models and types in schema.prisma. For example, this is how the schema for two of the tables in AI-Daleel is defined:
model Verses {
id String @id @unique
verseText String
verseTranslation String?
verseNumber String
surahNumber String
}
model UserNotes {
id String @id @default(cuid())
snippetId String
savedSnippets SavedSnippets @relation(fields: [snippetId], references: [id], onDelete: Cascade)
content String
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
}
Table definitions in schema.prisma.
With these, CRUD operations can be done simply by calling methods on the Prisma Client object. In AI-Daleel, this is done on the server-side within a tRPC procedure. Here's an example of how you would use Prisma Client to fetch data from the UserNotes table in the database:
//Prisma Client query
const dbRes = await prisma.userNotes.findMany({
where: {
snippetId: input.snippetId
},
select: {
id: true,
content: true,
createdAt: true
}
})
For additional type-safety, you can also implement an interface to ensure that the database response conforms to the return type you require:
//In reality, this is defined in the global scope.
type RespT = {
result: string;
message?: string;
}
//In reality, this is defined in the scope of the tRPC procedure.
interface getNoteRespT extends RespT {
data?: {
content: string,
id: string,
createdAt: Date
}[]
}
//Initialize response object
let response: getNoteRespT;
//Query database using Prisma Client method
const dbRes = await prisma.userNotes.findMany({
where: {
snippetId: input.snippetId
},
select: {
id: true,
content: true,
createdAt: true
}
})
if (dbRes.length === 0) {
response = { result: "NO_SAVED_NOTES" }
} else {
response = { result: "NOTES_RETRIEVED", data: dbRes }
}
return response
As you can see, Prisma makes it convenient to query the database, as the ORM returns responses in the form of TypeScript objects which can be guarded by type definitions. This minimizes bugs that may arise from type mismatches and undefined responses.
On top of Prisma Client, Prisma comes with a powerful migration toolkit in the form of Prisma Migrate. It is a CLI tool which performs database schema migrations and implements safeguards against schema drift.
Essentially, when you run npx prisma migrate dev Prisma Migrate generates native SQL procedures and stores migration history in .sql files within the prisma\migrations directory. It acts as a "source of truth for the history of your data model". The npx prisma migrate diff command lets you compare the migration history and make necessary reverts to the schema definition, which is crucial in resolving schema drifts and migration history conflicts.
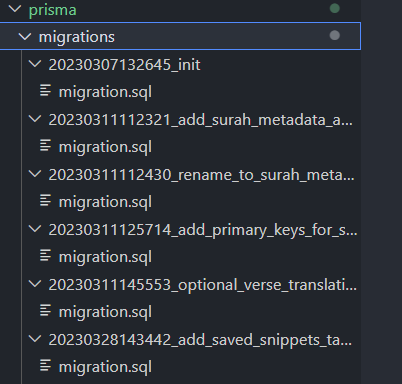 Prisma migration history.
Prisma migration history.
In order to switch between development and production databases in AI-Daleel, we assign the relevant environment variables (in this case, the URLs and the API keys) in the .env file to select the desired database to use for migration commands or runtime queries. This can be simplified further with a boolean config variable like PROD_ENV that can be used to programmatically assign the right environment variables during runtime.
On top of being a type-safe ORM, Prisma is an indisposable database management toolkit, as it simplifies processes by providing a set of DevEx-friendly CLI tools and configuration files-based workflows in place of conventional GUI-based database management.
Tailwind CSS
Now, let's talk aesthetics. There are many approaches to styling a web application in 2023, but they fall into two major categories. You can use frameworks that come with pre-made components like Bootstrap, or you can use frameworks that only provide utility classes without styling like Tailwind CSS. For AI-Daleel, we opted for the latter.
Tailwind CSS is an open-source 'utility-first' CSS framework that provides developers with the ability to write in-line CSS along with the application code, like in the .jsx snippet below:
<div className="w-full md:columns-2 lg:columns-3 items-baseline h-max space-y-10 mt-5 overflow-visible md:items-center md:align-top">
//Verse data code here
<VerseCard />
</div>
With just a handful of utility classes defined in the className of the div above, we were able to render a nice masonry layout as seen below:
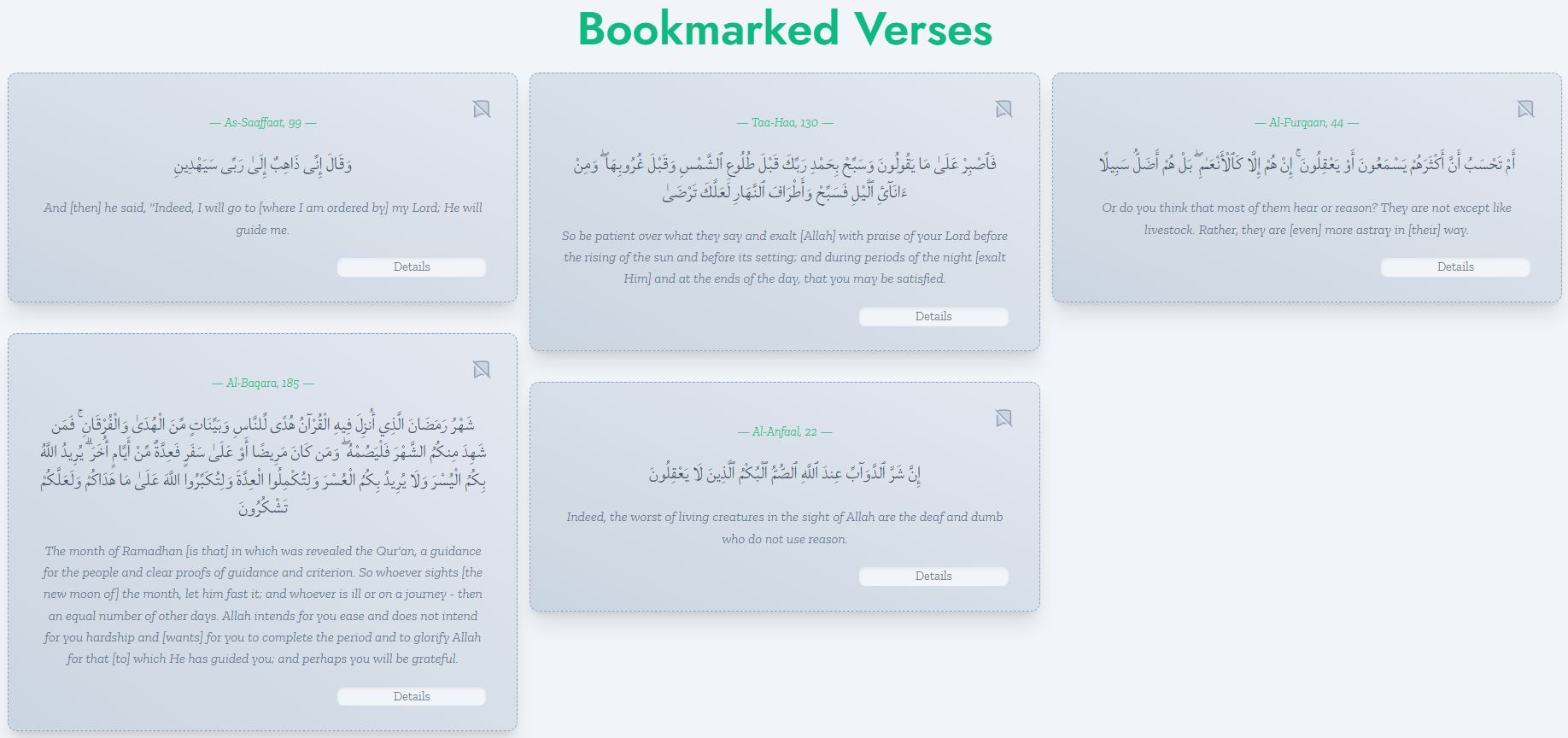
Purists might say that this is the 'wrong' way to write CSS. I say that I prefer to save time by not needing to go back and forth between files just to do some styling on my div. People have strong opinions about CSS and spend a lot of time debating on the 'right' way to style stuff, which I think is energy that could be well spent on more important matters.
"But what about reusability?", you might ask. Surely having to define an incantation of styles over and over again to style your divs will make your code ugly and unmaintainable, right?
Well, Tailwind does support the addition of custom component classes. Essentially, you can declare your own component classes in main.css by defining the @layer directive as below:
@tailwind base;
@tailwind components;
@tailwind utilities;
@layer components {
.card {
background-color: theme('colors.white');
border-radius: theme('borderRadius.lg');
padding: theme('spacing.6');
box-shadow: theme('boxShadow.xl');
}
/* ... */
}
However, doing this is considered anti-pattern as it defeats the purpose of using a utility-based CSS framework in the first place. Tailwind advocates for reusability via components. Having a React component VerseCard that contains style definitions ensures reusability, regardless of where the component is invoked from.
The Tailwind documentations provide us with a neat guideline on the best-practices on reusing styles.
NextAuth.js
Authentication and authorization are crucial core functionalities that need to be implemented in AI-Daleel. As each call of the OpenAI API comes with a cost, we need a reliable way to ensure that the calls are made from valid users and not bots. We also need a way to track usage and impose quota limits to avoid DDoS and spam. We also want to avoid rolling our own auth with just a simple email and a hashed password stored in database as it is not secure enough. For this, we will need to make use of a fully-fledged authentication framework.
NextAuth.js is an open-source authentication framework that aims to simplify the implementation of secure authentication for Next.js. It handles handshakes with third-party identity providers, manages client sessions via tokens and cookies, enforces token refreshes, among many other things.
It is tied to the database via Prisma, hence the session-related tables can be defined in schema.prisma along with other application tables.
model Account {
id String @id @default(cuid())
userId String
type String
provider String
providerAccountId String
refresh_token String? @db.Text
access_token String? @db.Text
expires_at Int?
token_type String?
scope String?
id_token String? @db.Text
session_state String?
user User @relation(fields: [userId], references: [id], onDelete: Cascade)
@@unique([provider, providerAccountId])
}
Account table used by NextAuth to handle user accounts in schema.prisma.
Due to inherent security risks, NextAuth strongly advises against the conventional credentials-based authentication, where hashed user passwords are stored in the application database along with the username. Instead, it advocates for the usage of authentication providers such as Google Auth, Auth0, and Azure Active Directory. For AI-Daleel, we use Google, GitHub, and Discord as our primary authentication providers. These are all big software companies with whole divisions that are in charge of authentication and responding to vulnerabilities, so we can be assured that our users are secure.
With NextAuth.js, we can simply define the authentication providers within the NextAuthOptions object which is passed along with the Next.js context object for each call between the server and the client.
providers: [
DiscordProvider({
clientId: env.DISCORD_CLIENT_ID,
clientSecret: env.DISCORD_CLIENT_SECRET,
}),
GoogleProvider({
clientId: env.GOOGLE_CLIENT_ID,
clientSecret: env.GOOGLE_CLIENT_SECRET,
}),
GitHubProvider({
clientId: env.GITHUB_CLIENT_ID,
clientSecret: env.GITHUB_CLIENT_SECRET,
}),
//Add more providers here.
]
Defining providers for NextAuth.
As the session object also gets passed along with the Next.js context, we can extend it to store additional information that we require for authorization purposes such as user role and quotas:
interface Session extends DefaultSession {
user: {
id: string;
// ...other properties
role: string;
searchQuota: number | undefined;
generateQuota: number | undefined;
bookmarkQuota: number | undefined;
} & DefaultSession["user"];
}
This means that on the client side, we can call useSession() to get user roles and quotas and respond accordingly:
const { data: session } = useSession();
const handleSearch = async () => {
if (session && session?.user.searchQuota !== 0) {
//Make API call
} else {
//Raise toast notification: out of quota for the day
}
}
NextAuth.js provides AI-Daleel with top-of-the-line security, maintainability, and flexibility when it comes to authentication and authorization. I am of the opinion that third-party identity-as-a-service (IDaaS) or authentication-as-a-service (AaaS) platforms like Supabase Auth and Clerk, which store user data on behalf of you, are not suitable for AI-Daleel. This is because AI-Daleel needs to handle quota logic as a means of authorization for most user actions. Therefore, it requires all the user data to be localized and tightly coupled with the rest of the application data in our own database for better performance. NextAuth.js avoids this by merely acting as an interface to various authentication providers while keeping user data in the application database.
OpenAI API
The brains of AI-Daleel is the GPT model developed by OpenAI. Specifically, it's the gpt-3.5-turbo-0301 model published in March. At the time of development, it was the most performant model while also being the most economical at only 1/10th of the price of text-davinci-003, which is another model with similar performance.
GPT-3.5 is also not fine-tunable through the OpenAI API, but this is fine as for our use case, as a little prompt engineering can already yield great results. In the context of the OpenAI GPT API, fine-tuning simply means providing a pair of prompt and expected response to the model:
{"prompt": "<prompt text>", "completion": "<ideal response text>"}
{"prompt": "<prompt text>", "completion": "<ideal response text>"}
{"prompt": "<prompt text>", "completion": "<ideal response text>"}
...
Providing hundreds of thousands of entries like this will result in a more specialized (fine-tuned) model.
That being said, a future improvement to be considered for AI-Daleel is to fine-tune the model by using tools such as LangChain to add our own tokenized documents on top of the original GPT embeddings. The customized embeddings can then be stored in a dedicated vector store such as ChromaDB.
In AI-Daleel, we simply provide instructions to the model using the official Node.js library from OpenAI. Then, we simply invoke something like the following in our corresponding tRPC protected procedures:
//Import from the library
const { Configuration, OpenAIApi } = require("openai");
//Pass secret key into the configuration object
const configuration = new Configuration({
apiKey: env.OPENAI_SECRET_KEY,
})
//Instantiate a new OpenAIAPI object and pass in the configs
const openai = new OpenAIApi(configuration);
//Craft your prompt
const prompt = "Insert your prompt here. Prompt engineering is needed to reliably instruct the model."
//Make the inference call
const openAiRes = await openai.createChatCompletion({
model: "gpt-3.5-turbo-0301",
messages: [{"role": "user", "content": prompt}]
})
AI-Daleel requests the OpenAI API to return the results in a JSON format. Therefore, it is important to do some server-side processing to ensure that no broken response is sent to the client, and if any unexpected response is received, the right toasts will need to be risen on the client side. This way, the app will be secure from LLM-specific vulnerabilities such as prompt injection.
try {
console.log("DATA: ", data);
const respObj = JSON.parse(data.replace(/[\n\r]/g, '') as string);
if (JSON.stringify(respObj) === JSON.stringify(defaultRes)) {
res = { result: "INVALID_PROMPT", message: "Prompt input invalid. Please retry with a different prompt." }
} else if (respObj.length > 3) {
res = { result: "LENGTH_MOD_PROMPT_INJECTION", message: "Prompt input invalid. Don't inject my prompt bro." }
} else {
res = { result: "SEARCH_SUCCESS", message: `AI Search successful. You have ${quotas.searchQuota-1} AI Search quota remaining.`, respObj: respObj }
}
}
catch (e) {
console.log(e)
res = { result: "BROKEN_RESPONSE_ARRAY", message: "Prompt input invalid - broken response array. Please retry with a different prompt." }
}
Parsing the response on the server.
Database
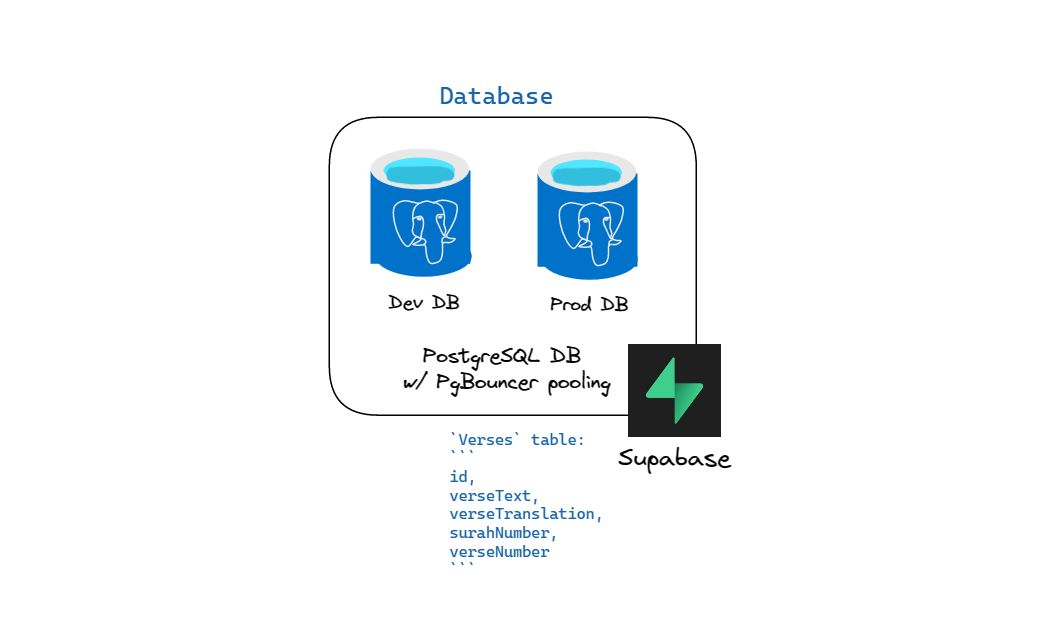 AI-Daleel database stack.
AI-Daleel database stack.
AI-Daleel needs a database to store the application data, Quranic verses, and user accounts. The project requires a performant, scalable, and most importantly, cost-effective database solution.
We turned towards Supabase for its generous free-tier PostgreSQL database hosting. It provides 512MB of free database space, and up to 2GB of data egress.
On top of that, it provides connection pooling capability with PgBouncer. Connection pooling is a way to manage a large number of temporary connections made by end users. Conventionally, when a client wants to perform a database transaction, it would need to open a connection to the database, perform the transaction, commit the transaction, and close the connection. There is a lot of overhead compute and network costs involved with opening and closing a connection to the database, and this is compounded for each additional user.
Connection pooling solves this by having a cached collection of open database connections that can be borrowed on-demand and returned to the pool for reuse by another client. This avoids having to open and close the connection for each individual transaction, which is are expensive operations.
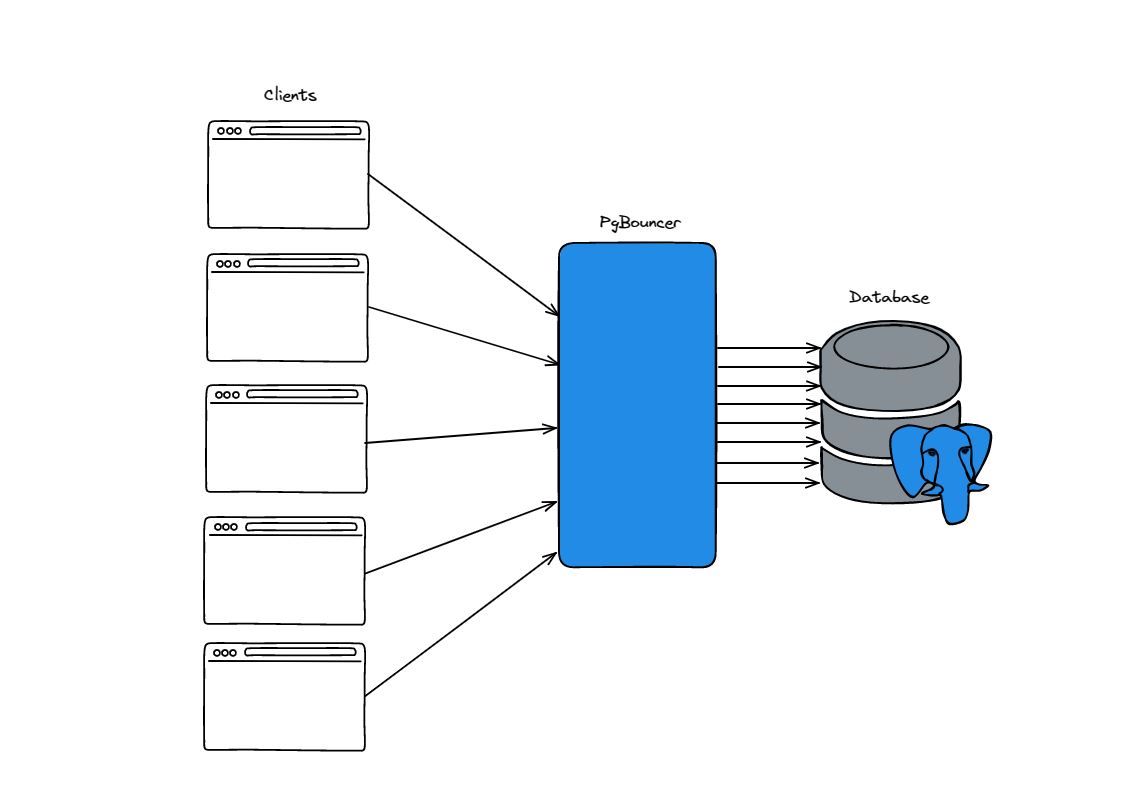 Connection pooling with PgBouncer.
Connection pooling with PgBouncer.
Supabase, being an open-source project, has a lot of community support. This includes a Python client library that we can use to create Python scripts to run maintenance transactions on the PostgreSQL database.
AI-Daleel makes use of two separate PostgreSQL databases hosted on Supabase — one development database and one production database. Dealing with PostgreSQL means that whenever we need to migrate data from the production environment into the development environment, we can use tools like pg_dump and psql that are shipped along with the standard PostgreSQL distribution:
pg_dump -h {host_name} -U {db_user_name} > {file_name}.sqlto dump the data from the hosted database into a local.sqlfile.psql -h {host_name} -U {db_user_name} < {file_name}.sqlto insert the data from the local.sqlfile into the destination database.
Serverless function
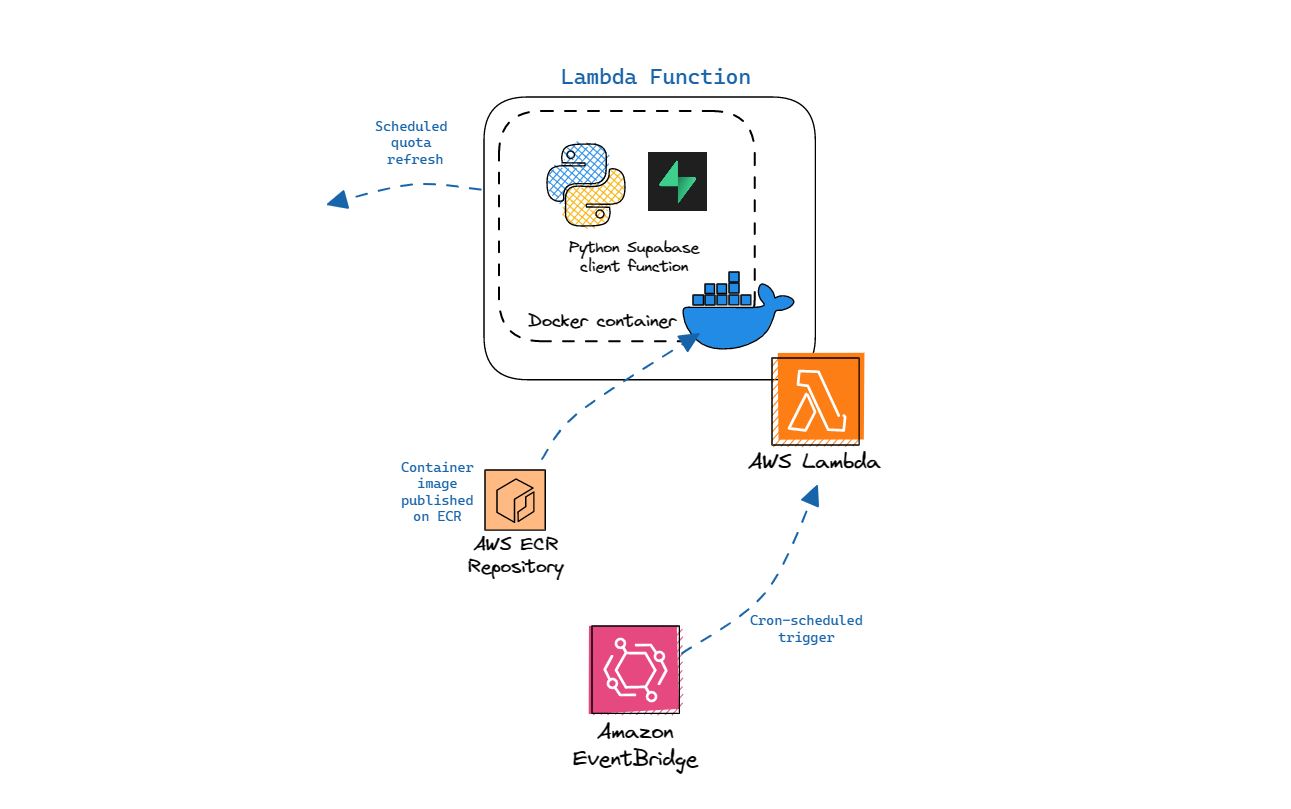 AI-Daleel Lambda function.
AI-Daleel Lambda function.
Users of AI-Daleel have a limited quota for actions like verse search and notes generation. Upon the depletion of the quota, users will have to wait until the quota gets replenished. This is done on a daily basis. Therefore, we need a way to run database transactions to update user quotas at a specified time every day.
For AI-Daleel, we are using AWS Lambda for this daily operation. It is a service from Amazon which allows us to run serverless code that can be invoked based on pre-specified triggers or events. Again, this comes at a benefit of cost-efficiency over conventional VM/VPS-based solutions like AWS EC2 that needs to be run every second. In fact, we only need the code to run for a few seconds every single day, and AWS Lambda is the perfect solution for this.
 CloudWatch metrics for AI-Daleel's quota refresh Lambda.
CloudWatch metrics for AI-Daleel's quota refresh Lambda.
We deployed a Python Supabase client function within a Docker container on AWS Lambda. You can find the repository on my GitHub, along with the Dockerfile and dependencies in requirements.txt. Essentially, the code uses the Python Supabase client library, and performs the update operation in just 22 lines of code (including imports):
from supabase import create_client, Client
import os
from dotenv import load_dotenv
from datetime import datetime
import json
def handler(event, context):
load_dotenv()
url: str = os.getenv("SUPABASE_URL")
key: str = os.getenv("SUPABASE_KEY")
time: str = str(datetime.utcnow())
supabase: Client = create_client(url, key)
res = supabase.table("User").update({
"searchQuota": 5,
"quotaRefreshTs": time
}).eq("role", "FREEUSER").execute()
//For monitoring purposes in AWS Lambda console
return json.dumps(res, default=str)
The repository is Dockerized and the container image is published on Amazon Elastic Container Registry (ECR). From there, we can create a new Lambda by supplying the URI of our container image in the Lambda console.
In order to trigger this Lambda, we use Amazon EventBridge Scheduler, which allows us to effectively set a cron-based schedule to run the Lambda once every single day.
The combination of AWS Lambda and Amazon EventBridge is a great and cost-effective solution if you need to run code or worker services on a scheduled basis, and for AI-Daleel we have paid a grand total of $0 since the deployment of the application, since the first 1 million invocations of each month are free. As we only need to run this code 31 times at max per month, we are well within this quota.
Conclusion
This has been a very technical in-depth post about the system architecture of AI-Daleel. Laying it down in words helped me better retain my experiences and learnings that I have obtained throughout the development of this project.
In a blog post from Simon Willison, he proposed the definition of being "done" for anything we build is after we "write about it". While I am nowhere near being "done" for AI-Daleel, I hope this blog post has served as a good write-up of my experiences and technical considerations in building this project.
Thank you for reading!